이 논문은 개인적으로 굉장히 어려웠다. 그래도 수식적으로 이어나가다 보니 이해가 되긴 하였고, 이 지식을 복습하고자 작성한다.

Abstract
이 논문에서는 nonequilibrium thermodynamics로부터 고안된 잠재 변수 모델 중 하나인 diffusion probabilistic models를 제안한다.
이 diffusion probabilistic model은 high quality image synthesis를 수행 할 수 있다.
이 논문에서는 diffusion probabilistic model과 Langevin dynamics의 denoising score에 적절한 connection을 사용한다.
Introduciton
요약
간단히 결론부터 설명하면 DDPM은 주어진 이미지에 time에 따른 상수의 파라미터를 갖는 작은 가우시안 노이즈를 time에 대해 더해나가는데, image가 destroy하게 되면 결국 noise의 형태로 남을것이다. (normal distribution을 따른다.)
이런 상황에서 normal distribution 에 대한 noise가 주어졌을때 어떻게 복원할 것인가에 대한 문제이다.
그래서 주어진 Noise를 통해서 완전히 이미지를 복구가 된다면 image generation하는 것이 된다.
NCSN과 같은 Score Matching 공부를 하고 다시 보니 안보이는 것들이 보인다.
이 논문에서는 diffusion probabilistic models의 과정을 보여준다. diffusion model은 유한한 시간 뒤에 이미지를 생성하는 variational inference을 통해 훈련된 Markov chain을 parameterized한 형태이다. Markov Chain은 이전의 샘플링이 현재 샘플링에 영향을 미치는 P(x|x) 형식을 의미한다.
그래서 이 diffusion model에서의 한 방향에 대해서는 주어진 이미지에 작은 gaussian noise를 점진적으로 계속 더해서 완전히 image가 destroy 되게하는 과정을 의미한다.
Background
Diffusion models는 수식적으로 접하여 이해할 필요가 있다.
우선 이 논문에서 제시하는 forward process(diffusion process)와 reverse process를 이해해보자.
1. 직관적으로

Forward Process
우선 주어진 이미지를 \(x_0\)이라고 하자.
그럼 서서히 noise를 추가해가는 과정을 \(q\)라고 해보자.
그럼 \(x_0\)에 noise를 적용해서 \(x_1\)를 만드는 것을 \(q(x_1|x_0)\)이라고 표현 할 수 있다.
이를 time t에 대해 general 하게 표현한다면 \(q(x_t|x_{t-1})\)으로 표현할 수 있다.
이를 forward process(diffusion process)라고 부른다. 이 때 끝까지 가면 \(x_T\) 즉 완전히 destroy 된 형태가 나온다.
이는 normal distribution \(N(x_T; 0, I)\)를 따른다.
Reverse Process
Reverse process는 이 제목 그대로 \(q\)와는 반대로 noise를 점진적으로 걷어내는 denoising process이다.
그래서 \(q(x_t|x_{t-1})\)와는 반대로 time이 뒤바뀐 \(p(x_{t-1}|x_t)\)로 표현이 된다. 이는 자명하다.
주의할 점. \(x_t\) 들은 서로 resolution이 같다.
2. 수식으로
자 이제 수식으로 표현을 해보자.
Forward Process
Forward process의 의미는 점진적으로 gaussian noise를 추가하는 것 이라고 했다.
그래서 \(q(x_t|x_{t-1})\)은 \(x_{t-1}\)이 주어졌을 때 \(x_t\)가 어떻게 나올 것 이냐는 건데, 이는

이 식으로 표현이 된다.
여기에 beta는 variance schedule이다. (time에 따라 달라지는 값이고, constant처럼 적용됨.)
우리가 gaussian distribution에서 reparameterize를 통해 sample하게 되는 형태를 생각하면 저 식은 자연스럽다.
$$ x_t = \sqrt{1 - \beta_t}x_{t-1} + \sqrt{\beta_t} * \epsilon $$
이 형태로 \(x_t\)를 뽑아낼(?) 수 있기 때문.
그리고 여기에서 \(q(x_{1:T}|x_0)\)의 joint 된 형태로 표현하면 아래와 같다.
(이는 Bayesian Network의 Cascade 구조룰 살펴보면 알 수 있다.)

여기까지가 전반적인 forward process의 수식적 표현이다.
Reverse Process
자 이제 forward process를 봤으니 Reverse Process에 대해서 살펴보자.
이제 위의 어느정도 흐름은 파악 했을 테니 번거로운 세세한 설명들은 빼고 말해보면,

Reverse Process의 Joint된 형태와 조건부 확률은 다음과 같다.
이제 이 모델의 목적을 생각을 해보면, 결국 주어진 noise에 대해 어떻게 noise를 점진적으로 걷어낼 것이냐의 문제이기 때문에, 우리는 그 방법을 위의 p를 통해서 해결 할 것이다.
\(x_t\)가 들어왔을 때 \(x_{t-1}\)을 예측할 수 있게 된다면, 우리는 \(x_0\) 또한 예측 할 수 있다.
그리고 그 과정은 mean과 variance를 파라미터를 갖는 Gaussian에 대해 이루어진다.
그러므로 우리는 mean과 variance를 구하면 된다. 그래서 위 식은 가우시안 에서의 mean과 variance를 예측한다.
그래서 이 문제를 어떻게 해결할거냐면, Variational inference를 사용할 것이다.
generative model인 만큼 생성된 이미지의 log likelihood를 최대화하면 되는데, (data distribution에 알맞은 이미지 인가에 대한 측도)
이를 논문에서는 negative log likelihood로 최소화하는 방안으로 표기한다.
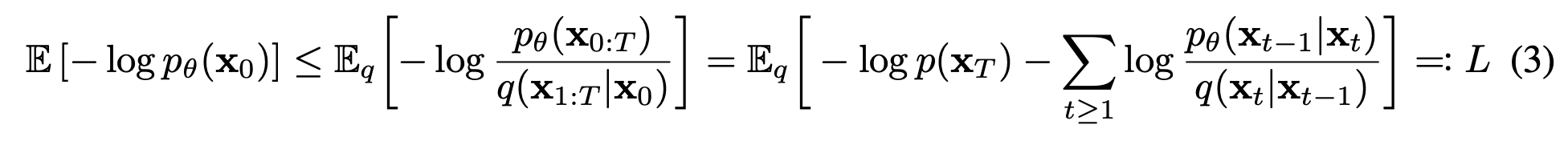
수식에 의해 Variational bound는 우항과 같이 나오고 이를 풀어내면

이와 같은 결과가 나온다.
특이한 점은 forward process의 posterior와 reverse process를 KL Divergence를 통해 직접 비교한다는 것이다. 생각해보면 우리는 forward process에 대한 정보를 가지고 있고 forward process의 posterior는 reverse process와 연관이 깊은 형태이기 때문에 tractable하다.
참고로 위의 식의 유도는 Appendix에 나와있다. 물론 한번 유도를 꼭 해보는 것을 추천한다. 본인도 유도를 해서 봤을 때 느끼는 점이 더 많았었음.

위 식의 \(\bar \alpha\)는 구하기 힘들어 보이지만, Torch.cumprod 함수를 통해 손쉽게 계산이 가능하다. 이러한 라이브러리를 잘 활용하는 습관을 들여보자 ㅎㅎ
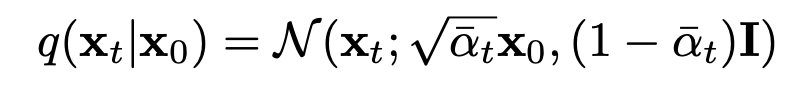
그리고 생각을 하고 있어야 할 점이 Appendix에서 posterior를 전개함에 있어서 \(q(x_t|x_0), q(x_{t-1}|x_0)\)을 사용하곤 하는데 이는 위처럼 표기가 가능하다. 우리는 time에 따른 \(\beta\)를 constant처럼 사용하기 때문에 \(x_0\)으로부터 \(x_t\)를 도출해낼 수 있다.
왜 posterior가 이런식으로 나올까? \(x_t\)를 \(q(x_t|x_{t-1})\)의 식을 가지고 \(x_0\)에 대한 식이 나올 때 까지 쭉 풀어보면 이러한 식이 나온다. (일정한 규칙을 가지고 풀린다.) 근데 이 때 이 식을 풀기 위해서는 gaussian distribution에서 가져온 노이즈끼리 더했을 때 어떤 성질을 가지는지 알아야한다. https://lilianweng.github.io/posts/2021-07-11-diffusion-models/ 이 블로그를 봐보자.
그럼 위의 Variational bound에 대해 생각해보자
Diffusion models and denoising autoencoders
Forward process and \(L_T\)
논문에서는 forward process variances인 \(\beta\)를 learnable한 파라미터로 두는게 아니라 상수로서 Fix하기 때문에 \(L_T\)는 고려를 하지 않아도 된다.
Reverse process and \(L_{1:T-1}\)
이제 \(L_{t-1}\)에 대해서 생각해보자.
수식을 살펴보면 \(q(x_{t-1}|q_t,q_0)\)과 \(p_\theta(x_{t-1}|x_{t})\)를 비교한다. 특이한 점은 \(q(x_{t-1}|q_t,q_0)\)가 posterior형태로 forward process의 반대 방향이라는 점이다.
우리는 forward process를 reparameterize를 통해서 \(\epsilon \sim N(0,I)\)로 표현을 할 수 있었는데, 이 반대의 process 또한 가능하다. (\(\epsilon\)에 대한 affine 형태이기 때문에)

논문에서 q를 위처럼 표기한다.
위의 식은 간단? 하다. (물론 혼자 손으로 쓰라고 하면 못쓴다 ㅋㅋ;)
위에서 우리는 \(q(x_t|x_0)\)에 대한 가우시안 분포를 잘 안다. 위의 q posterior를 bayes rule로 잘 주물럭거리면 우리가 아는 가우시안 분포들로 표현할 수 있다. Gaussian distribution끼리 bayes rule 적용하면 켤례성으로 결과도 Gaussian distribution이다. 이 성질로 식 써가다보면 위와 같은 형태가 나온다.
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/ 이것도 이 블로그 봐보자
우리는 \(q(x_{t-1}|q_t,q_0)\)에 대한 정보를 알고 있으므로 \(p_\theta(x_{t-1}|p_t)\)에 대해 알아보도록 하자.
위에서 말했듯이 우리는 \(p_\theta(x_{t-1}|p_t)\)를 Gaussian distribution으로 표현을하고 \(N(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))\) 로 표현할 수 있다.
$$ p_\theta(x_{t-1}|p_t) = N(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))$$
우선 첫번째로 \(\Sigma_\theta(x_t, t) = \sigma^2_tI\) 이다. 여기에서 \(\sigma^2_tI\)는 time dependent constants로 훈련에 참여되지 않는다.
아 참고로 논문에서는 실험적으로 발견한 것은 수식적으로는 \(\sigma^2_t\)를 \(\tilde \beta_t\)로 표현하는게 맞지만 \(\beta\)로 사용해도 별 다를점이 없다고 한다.
그러므로 mean \(\mu_\theta(x_t, t)\)만 고려하자.
이를 기반으로\( L_{t-1}\)을 아래처럼 쓸 수 있다.
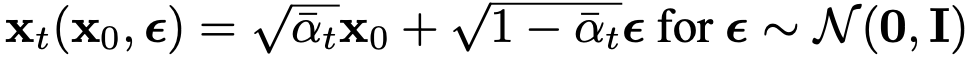


여기 식을 보면 expectation의 기준이 q에서 \(x_0\)와 \(\epsilon\)으로 달라지는데, forward process에 있어서 어떤 time에 대한 Gaussian Distribution이 time과 \(x_0\)만 주어진다면 reparameterize를 통해 표현 할 수 있기 때문에 이렇게 표현하는 것은 자연스럽다.
그리고 우리는 gaussian distribution의 mean을 의미하는 파라미터 \( \mu_\theta\)조차도 직접 예측할 필요가 없다. 왜냐면 이 \(\mu\)또한 reparameterize에 의해 \(\epsilon\)으로 표현할 수 있기 때문이다.
결국 이 논문에서는 해당 time에서의 \(\epsilon \)만을 예측해서 noise \(epsilon\)을 통해 time t에 맞게 sampling을 해낸다. (denoising)
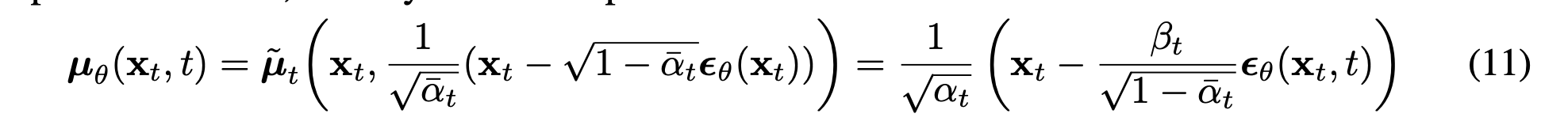

그래서 마지막으로 최저고하 하는데 있어서 time t에서의 \(x_t\)와 time 정보 \t를 network에서 input으로 받고 해당 \time에 맞는 noise를 추정하게 된다.
loss를 위와같이 사용한다. (이론 상으로는!)

그래서 이에 따라 training과 sampling을 위처럼 지정하는데, 우리는 discrete한 time \(t\), \(\epsilon\), \(x_0\)에 대해 expectation을 고려해야하기 때문에 MC method에 기반하여 time을 uniform 하게 뽑는다. (noise와 data 또한 무작위로 뽑힌다.)
그래서 이에 대해 loss를 적용하여 optimize 한다.
그리고 network에서 noise를 적용했으니, reparameterize에 기반하여 해당 time에서 denoising한 sample을 얻기위한 sampling은 수식적으로 Algorithm 2의 4와 같다.
위 알고리즘에 따르면 실질적으로 p 모델이 사용되는 샘플링의 경우 해당 distribution의 mean과 variance가 필요하지 않다.
근데 분석했던 코드는 mean과 variance를 사용한다. 뭔가 아리송하다..
score matching 분야에서도 mean, variance를 사용하여 샘플링 한다. 사실 이론적으로 이렇게 샘플링하는게 맞기 때문에 그런듯 싶다. 그리고 코드는 남이 쉽게 알아보도록 작성하는 것도 중요하기 때문에 더 직관적인 형식인 mean, variance를 사용하는 형식을 따른 듯 싶다.
GitHub - lucidrains/denoising-diffusion-pytorch: Implementation of Denoising Diffusion Probabilistic Model in Pytorch
Implementation of Denoising Diffusion Probabilistic Model in Pytorch - GitHub - lucidrains/denoising-diffusion-pytorch: Implementation of Denoising Diffusion Probabilistic Model in Pytorch
github.com
주의할 점 !
코드 작성 시, Variational Inference의 ELBO 유도를 통해 나왔던 Equation (5)에 매칭이 되도록 코딩한다. (pdf처럼. mean, variance 개념으로 샘플링.)
- for문을 따라서 timestep에 대해 차례대로 진행한다. 임의의 t에 대해 설명한다.
1. t번째 과정의 \(x_t\), 그리고 t, 이에대해 예측한 noise 가 있다.
2. 이런 요소들을 가지고 \(x_0\)을 바로 가져올 수 있다. -> q 관련 수식 중에서 \(x_t\)를 \(x_0\)과 noise로 바로 가져오는 식이 있는데 이 식이 affine 형식이라 그냥 식을 이항해서 정리하면 유도해낼 수 있다.
3. 그럼 수식으로 유도된 \(x_0\), \(x_t\), t, noise를 갖게된다. 이 요소들이 있으면 q posterior로 \(x_{t-1}\)을 가져올 수 있다.
4. 위 과정 반복.
실제로 샘플링 할 때 noise를 걷어낸다는 느낌보다는 각 timestep에 대한 mean, variance 정보로 그 다음 timestep에 대해 샘플링 하는 느낌이다. (사실 이게 noise를 걷어내는 거임.)
GitHub - lucidrains/denoising-diffusion-pytorch: Implementation of Denoising Diffusion Probabilistic Model in Pytorch
Implementation of Denoising Diffusion Probabilistic Model in Pytorch - GitHub - lucidrains/denoising-diffusion-pytorch: Implementation of Denoising Diffusion Probabilistic Model in Pytorch
github.com
이 코드를 봐보자!
이러한 sampling을 Ancestral Sampler라고 부른다.
time t에 대해서만 dependent한 sigma schedule을 가지고 있다. 때문에 forward process는 p(xi | xi-1) 형태가 됨을 알 수 있다.
이러한 transition kernel에 대해 posterior를 구하면 reverse process에 대핵서도 잘 알 수 있게 된다.
이 수식적으로 구해놓은 posterior에 대해 훈련시켜 놓은 noise model을 샘플링할때 어떤 방식으로 사용해야할지 알아내면 된다.
이는 KL Divergence를 사용한다.
https://openreview.net/pdf?id=PxTIG12RRHS 의 APPENDIX F ANCESTRAL SAMPLING FOR SMLD MODELS 에서는 NCSN 기반의 모델에 대한 Ancestral Sampler 수식을 구하는 과정을 보여준다.
Data scaling, reverse process decoder, and \(L_0\)
논문에서는 사용되는 image data가 8 bit rgb로, integer[0, 1, 2, ..., 255]로 이루어져 있으며, 이를 [-1,1]로 선형적으로 scale 시킨다고 가정한다.
이는 standard normal prior \(p(x_T)\)로 부터 denoising 과정을 통해 마지막 output을 꺼낼 때 이 구간에 대해 고려해야함을 의미한다. [-1,1]
discrete log likelihood를 빼내기 위해서 reverse process의 마지막 term \(p_\theta(x_0|x_1)\)을
Gaussian \(N(x_0; \mu_\theta(x_1, 1), \sigma^2_1I)\)로부터 이끌어진 독립된 discrete decoder로 정한다.
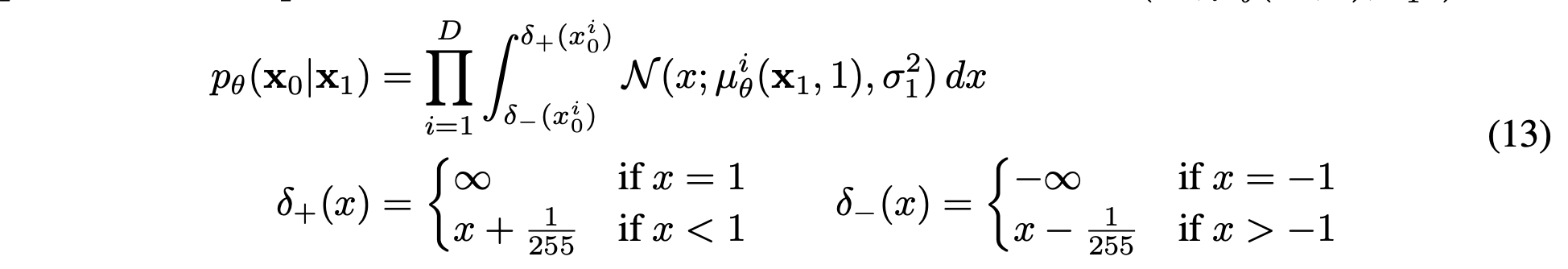
각 좌표 위치 i에 대해 autoregressive하게 진행 됨을 의미하는 것 같다. (이는 확실치 않음. 이해를 잘 못하겠음.)
어쨌든 이론적으로는 위 수식을 사용하게 되는데, 사실 실제 사용할 때는 이를 적용하지 않는다.
Simplified training objective
위의 수식적, 이론적인 실행이 아닌 좀 더 간단화된 loss를 사용해서 더 나은 quality를 얻었다고 한다.
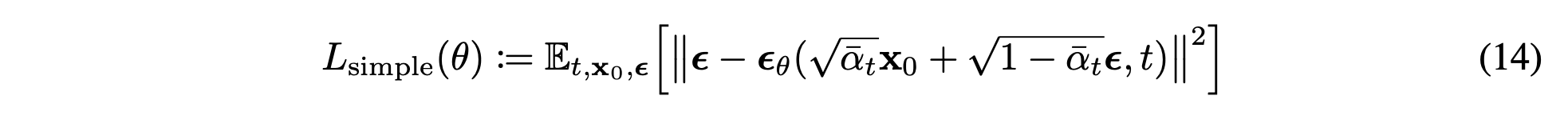
이 식에서 t= 1이면 \(L_0\)에 대응된다. 그리고 \(\sigma^2_1\)는 무시된 형태이다.
Algorithm 자체는 위에 제시한 방법과 동일하다.
Experiment
Experiment Setting
T = 1000
\(\beta = 10^{-4}\) to \(\beta_T = 0.02\)
UNet Backbone with group normalization
Parameters are shared across time, which is specified to the network using the Transformer sinusoidal position embedding
use self-attention at the 16 x 16 feature map resolution
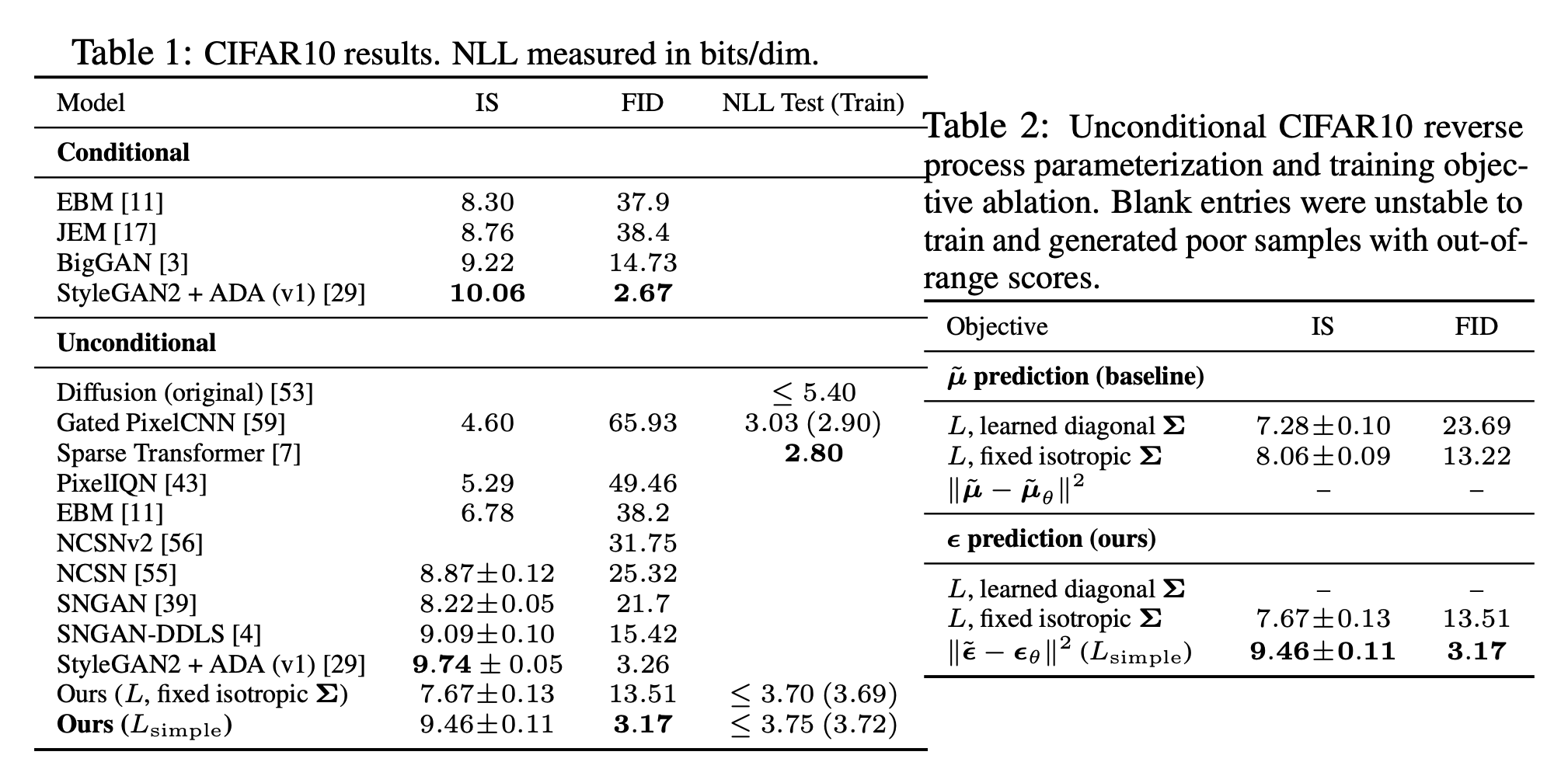
사실 T는 더 많이 줘야한다. 이는 Improved DDPM 논문에 나와있는 내용이다. p의 var를 beta로 퉁쳐버리기 때문에 생기는 현상.
이에 대해서는 또 다른 포스트로 기술하겠다.
논문 뒷부분에서 신기했던점 ?

Large scale image features는 처음에 나타나고, 세세한 정보는 나중에 나타남.
Interpolation

논문에서는 source images \(x_0, x^{'}_0 \sim q(x_0)\)을 interpolate 하는 법을 제안함.
\(x_t, x^{'}_t \sim q(x_t|x_0)\) -> noise를 추가함.
이 \(\hat x_t = (1-\lambda)x_t+ \lambda x^{'}_t\)로 만들어서 \(\hat x_0 \sim p(x_0)|\hat x_t)\)을 샘플링
이렇게 하면 latent space에서 linearly interpolate하여 자연스럽게 interpolated된 이미지를 sampling 할 수 있다.
논문에서는 \(\hat x_t = (1-\lambda)x_0+ \lambda x^{'}_0\)로 표기 되어있어서 헷갈렸다. 코드 살펴보니 오타인듯 싶음.
'Generative Model' 카테고리의 다른 글
| Generating Diverse High-Fidelity Images with VQ-VAE2 (0) | 2021.09.20 |
|---|---|
| Neural Discrete Representation Learning : VQ-VAE (0) | 2021.09.17 |
| Variational Auto Encoder를 이해해보자! (3) (0) | 2021.09.14 |
| Variational Auto Encoder를 이해해보자! (2) (0) | 2021.09.13 |
| Variational Auto Encoder를 이해해보자! (1) (0) | 2021.09.12 |



