Abstract
VQ-VAE와 기존 VAE와는 다른 점이 두가지 존재합니다.
- Encoder Network의 output이 discrete하다. 그리고 prior는 정적이기 보단, discrete representation을 학습한다.
- Vector Quantization을 사용한다. 이를 사용해보니 Posterior Collapse가 완화되었다.
Introduction
이 논문에서의 논점은 maximum likelihood에 대해 optimize하면서 latent space에서 data의 중요한 features를 보존하는 것입니다.
이 말을 보면 무슨 말인지 이해가 안갈 수 있습니다. 그렇다면 포스트를 한번 쭉 읽어보고 다시 이 문장을 봐보면 이해가 갈 것입니다.
여기에서 중요한 점은 discrete하고 유용한 latent variables를 learning하는 건데, 보통 vae나 gan 같은 생성모델들은 continuous latent variables에 대해서 학습을 진행합니다.
이 논문의 모델인 VQ-VAE에선 이런 연속적인 잠재 변수가 아닌 discrete한 잠재변수를 사용하겠다는 뜻입니다.
이 때 이 모델은 Vector Quantization을 사용하여 훈련하기 쉽고 큰 variance또한 겪지 않습니다. 그리고 무엇보다, posterior collapse를 avoid 할 수 있다는 것 입니다.
VQ-VAE
이 모델은 Posterior와 Prior가 Categorical distribution을 따른다고 가정합니다.
애초에 embedding space라는 것을 table 형태로 정해놓고 이 embedding space 또한 학습하게 됩니다.
Discrete Latent Variables
일단 latent embedding이 상주할 수 있는 table 형태의 latent embedding space부터 봐봅시다.
이 latent embedding space는 \(e \in R^{K \times D}\)로 표현됩니다. 여기에서의 뜻은 D dimension을 갖는 K개의 embedding vectors라는 의미입니다.

이 figure 1의 노테이션대로, encoder의 output은 \(z_e(x)\)로 표기합니다. 근데 이를 그대로 사용하면 discrete가 아니라 continuous를 사용하게 되겠죠? 그러니까 사전에 초기화시켜놓은 embedding space (table)에서 \(z_e(x)\)와 가장 가까운 친구를 가져와서 사용합시다. 이를 Nearest neightbour look-up이라고 합니다.

식으로 나타내면 eq 1 과 같습니다.
실제 이러한 Matching을 구현 할 때, (B, H, W, C) 형태의 shape을 갖는 Encoder output을 (B*H*W, C) 형태로 reshape시키고 이 B*H*W들이 모두 independent 한 것처럼 matching을 진행합니다. 그 다음 B*H*W 각각에 대해 가장 가까운 embedding space의 요소를 찾아서 indices를 뽑은 다음 이를 masking을 통해 해당하는 embedding space의 요소들만 유효한 값을 갖도록 해줍니다.

그리고 이 매칭된 discrete latent를 decoder의 input으로 들어가고 표현은 \(z_q(x)\)로 할겁니다.
Learning
근데 잘 생각해보면 의문이 하나 듭니다.
"아니 indices를 통해서 discrete한 latent를 뽑아왔는데 이걸 어떻게 역전파 때 훈련 시켜야하지??"
해결책은 간단합니다. Fig.1 좌측 그림의 빨간색 선처럼 decoder Input에서의 gradient를 그대로 가져옵니다.
엥 이래도 괜찮나..?
Fig1의 우측 사진을 봐봅시다.
우리가 discrete latent를 embedding space에서 encoder의 outputs들과 가장 가까이 있는 embedding factor들로 가져왔었죠?
잘 생각해보면, 가장 가까이 있는 요소에 gradient의 경향성을 부여하게 되기 때문에 유효한 효과를 낼 수 있습니다.

전체 loss는 이와 같습니다. 엥 근데 KL Divergence Term이 없습니다. 이 이유는 Prior를 uniform distribution으로 가정했기 때문에, KL Divergence Term은 상수가 됩니다. 그래서 훈련에 관여하지 않게 됩니다.
근데 우리는 인덱싱을 통해 어떤 discrete한 latent를 뽑아냈기 때문에, 위에서 backpropagation을 encoder로 전하는 법은 해결 했지만 embedding space (table)은 아직 학습하지 못합니다.
이처럼 Embedding space의 훈련이 어렵기 때문에 VQ라는 dictionary learning algorithm을 적용합니다.
위 전체 Loss를 보면 총 세 부분으로 이루어져 있습니다.
첫번째로, Reconstruction loss. 이는 encoder와 decoder 모두 훈련합니다.
이 두번째, 세번째 term이 이 VQ 기법과 연관이 있는데요. 논문에서는 이에 대해 잘 설명하고 있지 않습니다.
sg는 stop gradient를 의미합니다. (pytorch에선 detach 함수로 gradient를 끊어주면 됩니다.)
그래서 제가 느낀 나름대로 적자면, reconstruction loss에 대한 gradient가 decoder로부터 그대로 encoder output \(z_e(x)\)로 넘어와서 encoder도 훈련이 됩니다.
이렇게 되면 저희의 의도처럼 encoder가 update되는데 이 경향성 그대로 embedding space 또한 훈련하면 됩니다.
그래서 두번째 Term처럼 embedding space(table)가 encoder output인 \(z_e(x)\)에 가깝게 다가가면 되고, 세번째 term은 encoder를 embedding space (table)처럼 되도록 학습하는 것인데 이는 동일한 신호(중복되는,)가 embedding space의 요소에 매칭되지 않도록 하는 역할을 합니다.
Prior
그럼 Sampling 할 때 임의로 latent를 가져와야하는데, 이는 어떻게 수행해야할까요?
저도 엄청 와닿은 부분은 아니었는데, 코드를 참고 했습니다.
AutoRegressive model (논문에서는 PixelCNN)을 z에 대해 fitting 한 후에 해당 모델을 통해 z를 만들어냅니다.
이렇게 만들어진 z를 vae model의 decoder에 넣어 샘플링하면 됩니다.
이 방법으로 더 좋은 results를 내놓을 수 있었다고 합니다.
Appendix

위 그림은 Total Loss에서의 두번째 Term입니다.
이에 대해 생각을 해볼 때
$$ \sum^{n_i}_j ||z_{i,j}-e_i|| $$
해당 embedding space와 encoder outputs 중 매칭되는 것들 끼리 distance를 구하게 됩니다.
이 값에 대한 최적의 값은 해당 매칭된 거리들의 평균이 됩니다. 식으로 표현하면 아래와 같습니다.
$$ e_i = {1 \above 1pt n_i} \sum^{n_i}_{j} z_{i,j} $$
하지만 이렇게 바로 최적값을 구하는 것은 Minibatch를 통한 훈련이나, Online learning을 수행할 시 불가능합니다.
그렇기 때문에 EMA (Exponential moveing average) 방법을 제안합니다.
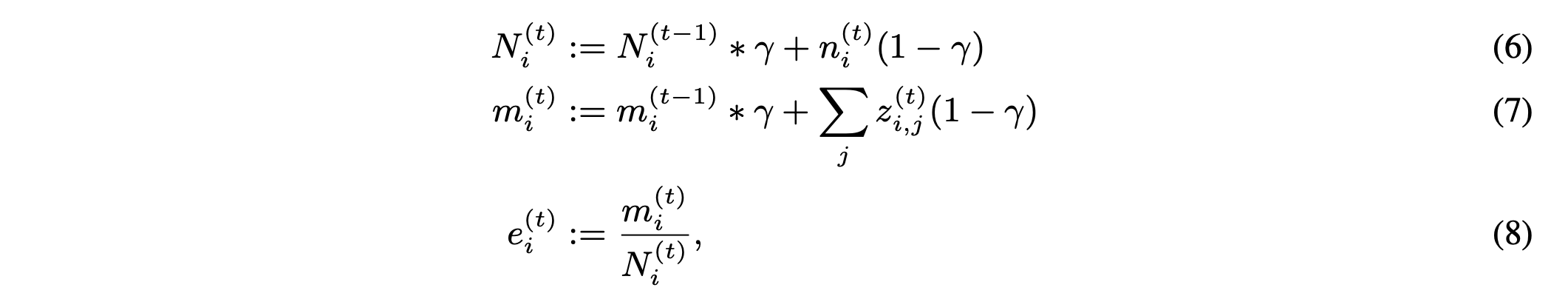
위 식이 VQ VAE의 EMA 과정을 나타낸다.
'Generative Model' 카테고리의 다른 글
| PixelCNN의 실행 흐름 (0) | 2021.09.22 |
|---|---|
| Generating Diverse High-Fidelity Images with VQ-VAE2 (0) | 2021.09.20 |
| Variational Auto Encoder를 이해해보자! (3) (0) | 2021.09.14 |
| Variational Auto Encoder를 이해해보자! (2) (0) | 2021.09.13 |
| Variational Auto Encoder를 이해해보자! (1) (0) | 2021.09.12 |


