SRGAN
시작하면서..
super resolution 분야에 대해 이전에는 SRCNN을 공부하고 포스트를 게시했었는데요, 이번에는 2017년도 굿펠로우 교수님이 엄청 신박한 발상으로 들고나오신 GAN을 이용한 Super Resolution GAN에 대해 공부하고 포스트를 게시하겠습니다.
SRCNN을 공부할 때, 그 논문에서 super resolution이 원래는 어떤 방식으로 이뤄졌으며, CNN은 동일한 작업을 할 수 있음을 비교하면서 보여줬었기 때문에 이번 논문은 전보다 비교적 쉽게 읽을 수 있었습니다.
역시 기초부터 하길 잘한 것 같습니다 ㅎㅎ
Abstract
존재하는 SR의 문제 : 더 세밀한 texture details를 복원 할 수 없을까??
Super Resolution 문제를 해결하는데는 loss function이 중요합니다.
기존의 Deep Learning을 통한 SR 방식은 MSE를 loss function으로 사용했습니다. 이는 high frequency detail과 지각적인 만족감이 떨어집니다. (pixelwise 방식이라서,)
이를 해결하기 위해 논문에서는 perceptual loss(adversarial + content loss)를 이용한 Gan을 소개합니다.
"The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images."
논문에서는 image의 매니폴드를 맞춰는 역할로서의 Adversarial Loss를 설명하고 있습니다.
"we use a content loss motivated by perceptual similarity instead of similarity in pixel space"
content loss는 지각적인 유사함을 표현하기 위함입니다. 앞에서 말했듯이 MSE를 사용하면 지각적인 유사함이라기 보다는 픽셀 간의 유사함이 표현되었겠죠?? (pixelwise)
SRGAN은 또한 deep residual network를 사용하여 무거운 downsampled image를 사실적인 texture를 처리할 수 있게 했습니다.
평가 방법으로는 Mean-opinion-score(MOS) test라는 방법을 소개합니다. (perceptual quality를 표현하기 위함.)
Introduction
기존의 방법 : minimization 하기 쉽고 PSNR을 maximize 할 수 있는 MSE를 사용해왔습니다. 이는 지각적인 문제를 발생시키고, pixelwise 기반이기 때문에 PSNR이 높다고 꼭 지각적으로 훌륭하진 않습니다. 아래 Fig. 2.를 확인해주세요.

PSNR (최대 신호 잡음비)
: 신호가 가질 수 있는 최대 전력에 대한 잡음 비
\(PSNR = 10\log_{10}({MAX_{1}^{2} \above 1pt MSE})\) Pixelwise 평가
참고 : https://bskyvision.com/392
Loss Function
MSE 대신 Adversarial Loss를 사용해야하는 이유를 Fig. 3.을 통해 봐보겠습니다.
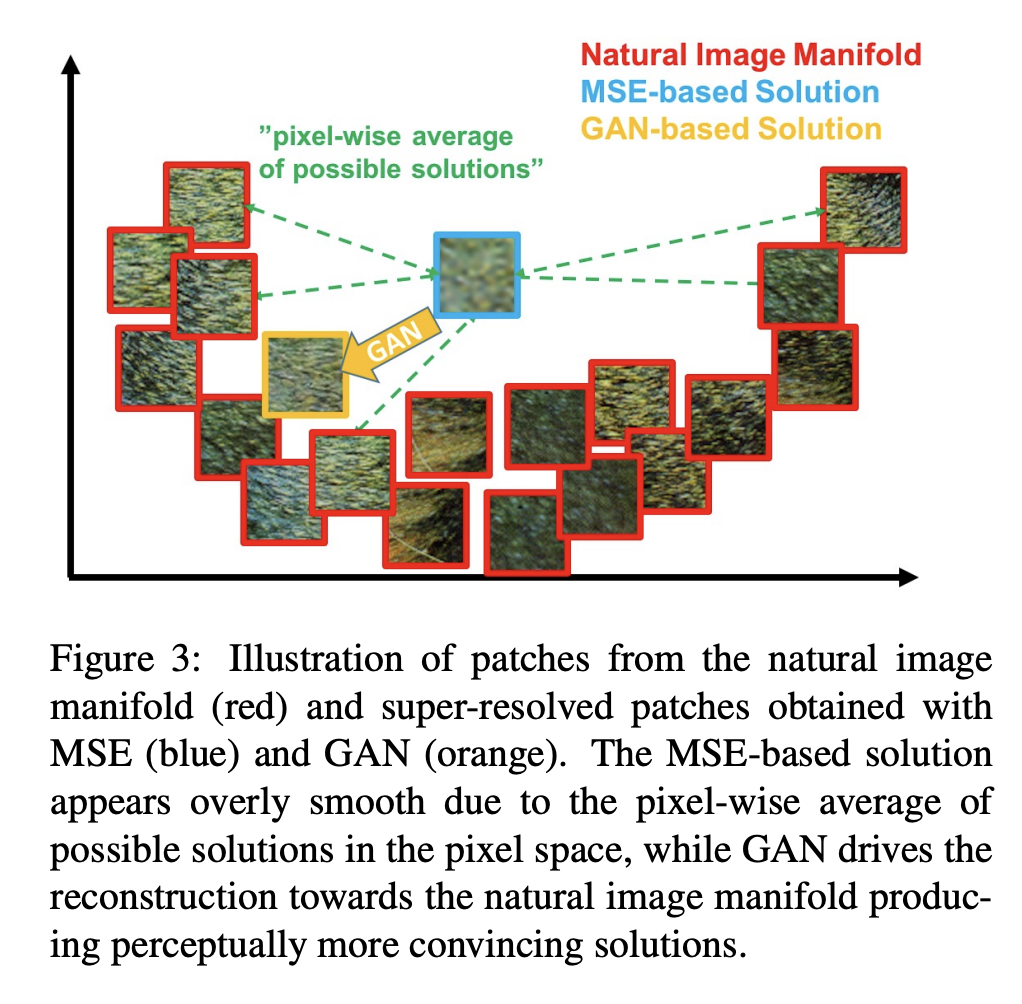
위와 같이 분포되어있는 Natural Image Manifold를 보시면, MSE는 균등하게 떨어져 있기는 하지만 포함되어 있지 않고 GAN은 해당 manifold 안에 포함되어 있는 것을 알 수 있습니다.
결국 복원된 이미지가 High Resolution Image에 대한 space로 가게끔 해주는 GAN-based solution이 지각적으로 더 훌륭한 결과를 낼 수 있음을 알 수 있습니다.
Method
SRGAN의 목표 : Gan의 Generator를 학습하여 주어진 LR input을 HR에 대응하게끔.
이를 수식적으로 표현하면,
$$ \hat\theta_G = \arg\min_{\theta_G}{1 \above 1pt N}\sum^N_{n=1}l^{SR}(G_{\theta_G}(I_n^{LR}),I^{HR}_n)) $$
이렇게 표현할 수 있습니다.
\(l^{SR}\) : Perceptual Loss
Adversarial network architecture
기본적인 gan의 loss function을 따릅니다.
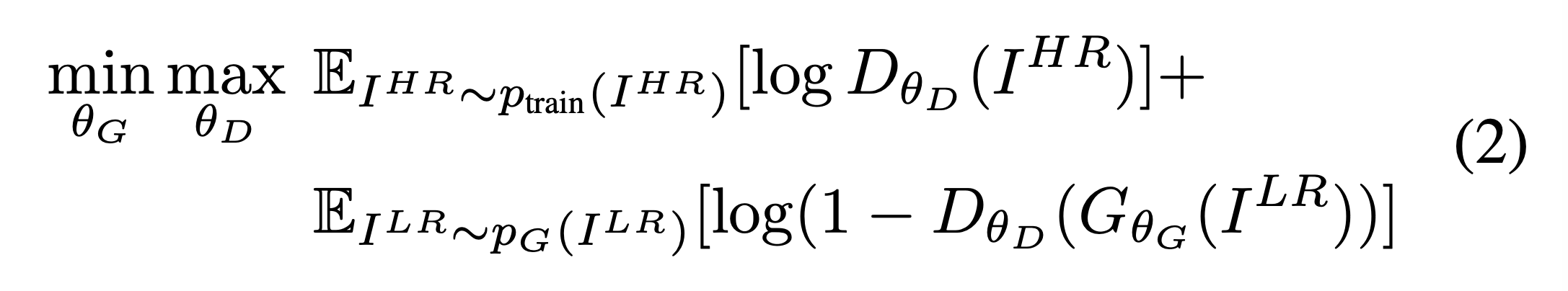
Adversarial loss는 지각적으로 우수한 결과를 냅니다.
Architecture

Generator는 Activation으로 PReLU를 사용합니다. (음수에 대한 gradient를 변수로 둔다.) 그리고 Residual block을 사용합니다.
Generator에서 조금 특이한 부분이 있는데, 이전의 SRCNN에서는 LR 이미지를 bicubic interpolation으로 크기를 HR 이미지와 동일하게 맞추고 input으로 넣었는데, SRGAN에서는 Generator 후반에 Pixelshuffler를 사용합니다.
https://pytorch.org/docs/stable/generated/torch.nn.PixelShuffle.html (pytorch doc)
(Cr^2, H,W) -> (C, Hr, W*r) Rearrange 시켜주는 것이라고 생각하시면 될 것 같습니다. r은 upscale factor로 PixelShuffle의 Argument 입니다.
Discriminator는 LeakyReLU(alpha= 0.2)를 activation으로 사용하고 maxpooling을 사용하지 않고 stride를 통해 크기를 줄여나갑니다.
Perceptual loss function
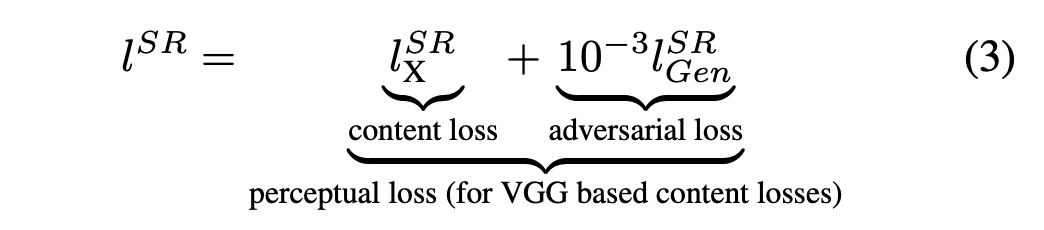
Content Loss
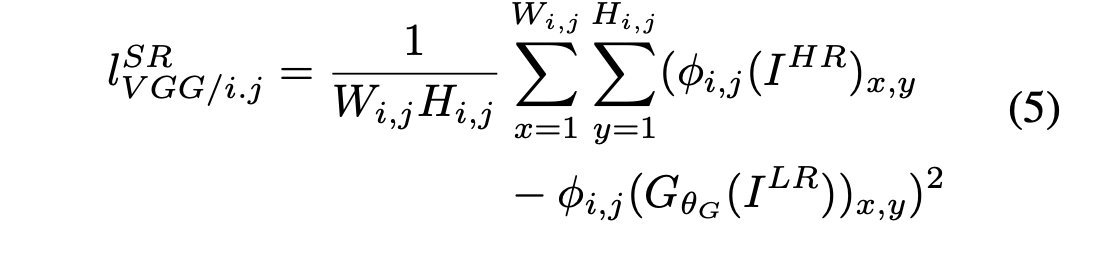
Content loss는 살짝 특이합니다.
\(\phi_{i,j}\)가 의미하는 바는 j번째 convolution(activation)이후, i번째 maxpooling레이어 전 부분의 feature map을 의미합니다. 하지만 SRGAN은 maxpooling layer가 없으니 몇번째 conv의 activation을 지났는지만 신경쓰면 됩니다.
저는 i,j = 2,2 로 뒀는데요, 그래서 discriminator 모델의 함수 부분에서 2번째 convolution을 지난 것을 return으로 같이 뽑아줬습니다.
Adversarial loss는 쉽게 알 수 있으니 생략 하겠습니다.
Experiments
benchmark datasets : Set5, Set14, BSD100
testing dataset : BSD300
Training details and parameters
ImageNet Database의 350 thousand images를 랜덤으로 뽑아서 훈련을 시행했고 LR image는 HR image를 downsampling 하여 얻었습니다.
그리고 LR input image의 스케일은 [0,1]이고, HR output image의 스케일은 [-1,1]이라고 합니다
Optimizer로는 Adam beta_1 = 0.9를 사용했고, learning rate는 10^5 iter까지는 1e-4로 설정하고 그 다음 10^5 iter는 1e-5로 바꿔서 실행합니다.
Discussion
얇은 Net 또한 효율적인 대안이 될 수도 있습니다. 층이 얇더라도 꽤 괜찮은 성능을 보이기 때문입니다.
반면에 Deep 하면 얻을 수 있는 장점이 있습니다. 상황에 따라 결정해서 사용하면 될 것 같습니다. (B>16)
Review
이번에는 SRGAN을 공부하고 리뷰해봤습니다. 제가 몇일 전까지 GAN만 쭉 팠었고 GAN을 공부하면서 SRGAN에서 좀 특이한 부분이라 할 수 있는 content loss에 대해 공부했던 경험이 있었습니다. 또, 이 SRGAN 논문을 읽기 바로 전에 SRCNN에 대해 공부하고 구현해봤기 때문에 다른 논문들보다 더 쉽게 와닿았고, 수월하게 읽을 수 있었던 것 같습니다.



