SRCNN
시작하면서..
2~3달 전부터 컴퓨터 비전 공부를 시작해보려고 그 중 하나의 방법인 gan에 대해서 한창 공부 했었습니다.
공부를 하다 보니 image generation 및 transfer 를 공부 한다기 보다는 Gan 자체에 얽매여 있었지 않았나 하는 생각이 들었습니다.
이제 제대로 딥러닝을 이용한 컴퓨터 비전 공부를 하기 위해서 딥러닝 컴퓨터 비전에서의 어떤 한 분야 씩 정해놓고 기초적인 논문을 읽고 쭉 파고 나갈까 생각하고 있습니다.
그래서 이번에 고른 분야는 저해상도 영상을 고해상도 영상으로 바꿔줄 수 있는 Super Resolution에 대해 공부하고자 합니다.
이번에는 super resolution in deep learning 에서도 가장 기본적인 SRCNN을 공부하고 리뷰해보려고 합니다.
Abstract
단일 이미지의 Super Resolution을 위한 딥러닝 방법으로 SRCNN을 소개합니다.
Low Resolution Image -> CNNs -> High Resolution Image
Introduction
SR은 ill posed 한 특성을 가지고 있습니다.
ill posed : 초기의 아주 작은 변화에도 최종 결과가 많이 바뀔 수 있는 특성** *
why ? Low Resolution은 변할 수 있는 여지가 크기 때문이다.
이를 해결하기 위해서 강력한 사전 지식으로 제한하는 방법을 제시합니다.
이러한 방법으로,
- 동일 이미지 내에서 유사성 도출
- high - low resolution pair image를 통해 mapping(CNNs)를 학습
이러한 방법들을 개척해나갑니다.
여기에서 두번째 방법을 이용한게 논문에서의 SRCNN 이라 생각하시면 될 것 같습니다.
SRCNN 특징
- 간단하면서도 좋은 성능
- CPU에서도 빠른 속도
- 더 많은 데이터와 깊은 모델로 성능을 높일 수 있음
Contributions
- fully confolution neural net 사용, end-to-end 방식
- 전통적인 방법과 SRCNN을 비교하여, 이 둘의 관계를 통해 Network에 대해 알 수 있음
- Deep Learning으로 SR에서 좋은 결과를 보일 수 있음.
전통적인 방법 : sparse-coding-based SR methods
sparse coding : 기저차원이 out의 차원 보다 큰 경우
기존 논문에서 추가된 점
- larger filter size & deeper structure
- three color channel로 확장
- 설명 추가.
Convolutional Neural Networks for Super-Resolution
기본적인 구조
$$
Y \rightarrow F(Y) \rightarrow X
$$
\(Y\) : 저해상도 이미지에 bicubic interpolation을 적용하여 고해상도 이미지의 크기와 동일하게 만든 input
\(F()\) : Mapping (CNNs)
\(X\) : CNNs에서 나온 결과 이미지
bicubic interpolation은 쌍삼차보간법이라고 불리는데, 자세한 설명은 https://bskyvision.com/789 이 포스트에 잘 정리 되있어서 보시는 걸 추천드립니다!
Relationship
이제 Contributions에 적혀 있듯이, 전통적인 SR 방법과 SRCNN을 비교하며 이해를 해보겠습니다.
- Patch extraction and representation
- CNN에서 input에 대한 feature map이 patch와 동일한 역할을 합니다. convolution 연산에 대해 생각해보시면 될 것 같습니다.
sparse coding based method에서 첫번째 패치를 dictionary에 사영(project)하는 것에서 input layer 작업과 동일함. 하지만 sparse coding based method는 feed forward 하지 않고, 반복적인 작업입니다.
- CNN에서 input에 대한 feature map이 patch와 동일한 역할을 합니다. convolution 연산에 대해 생각해보시면 될 것 같습니다.
- Non-linear mapping
- CNN의 hidden layer들을 통해서 비선형성을 추가해주는 부분이 전통적인 SR 방법에서의 Non-linear mapping과 비슷한 역할입니다.
- Reconstructure
- CNN에서 input layer와 hidden layers를 거쳐서 output layer를 통해 우리가 원하는 이미지를 복원 시킵니다. 이는 전통적인 SR 방법의 복원 과정과 같습니다.
Model
import torch.nn as nn
class SRCNN(nn.Module):
def __init__(self):
super(SRCNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 64, 9, padding = 4),
nn.ReLU(),
nn.Conv2d(64,32,1, padding = 0),
nn.ReLU(),
nn.Conv2d(32,3, 5, padding = 2)
)
def forward(self, x):
x = self.conv(x)
return x
논문 에서는 architecture로 3개의 레이어를 사용하는데 순서대로 kernel size를 9, 1, 5로 설정했습니다.
activation은 ReLU를 사용했으며, 마지막 레이어에는 추가하지 않았습니다.
Loss

loss function은 MSE Loss를 사용했습니다.
이미지에 대한 성능 측정 방법인 PSNR (최대 신호 잡음비)에 대한 역할을 할 수 있는 loss function이기 때문입니다.
이미지에 따른 목적에 대해서 성능 측정 방법을 달리 해야할 필요가 있는데요, SRCNN에서는 loss에 대해서 유연한 변화가 가능합니다. SSIM, MSSIM 등 여러 기준에 맞춰 손실 함수를 변화 시킬 수 있습니다. 물론 이는 'hand-craft'를 통해 이루어집니다... ㅜㅜ
Network Setting에 대한 고찰
시간, parameter 수 들과 성능의 trade-off 관계가 있으며, layer의 깊이는 꼭 깊다고 해서 좋은 성능을 갖지는 않습니다.

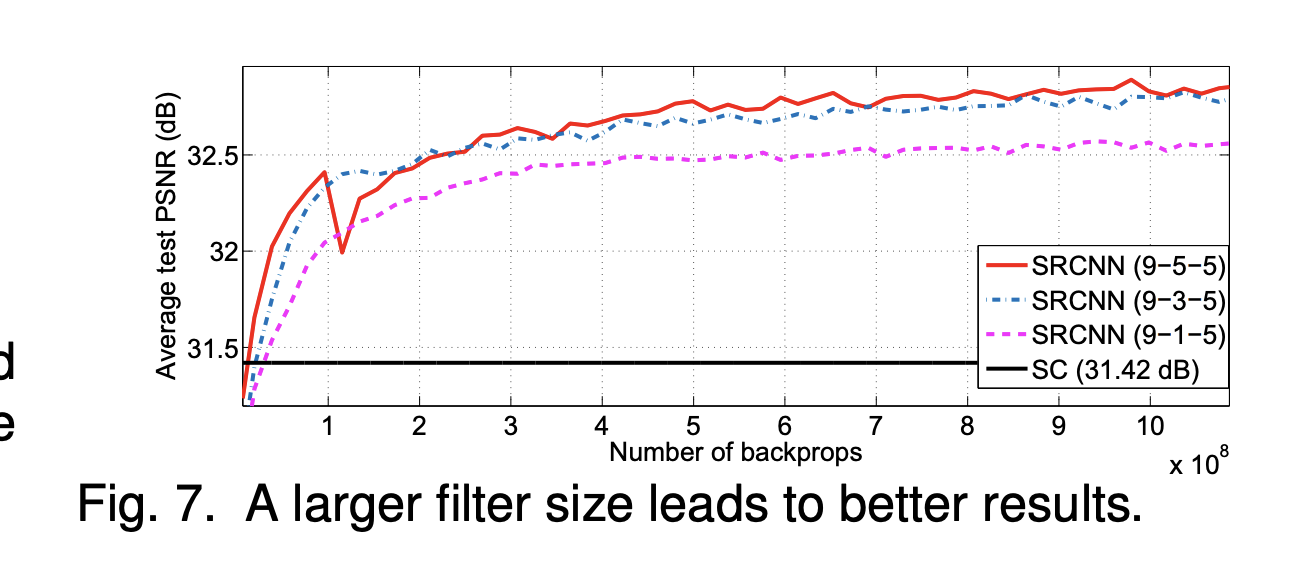
Fig. 4. Fig. 7.을 보시면 larger filter size, larger dataset이 더 좋은 성능을 이끌어 냄을 알 수 있습니다. 하지만 이만큼 걸리는 시간 및 계산해야 하는 양이 많아 지기 때문에 성능과 시간, 연산량에 trade-off 관계가 있다는 것을 알 수 있습니다.


Fig. 8. Fig. 9. 에서는 더 깊은 레이어가 그렇지 않은 레이어보다 성능이 좋지 않음을 보여주고 있습니다.
Result
이는 필자의 결과입니다.

bicubic 보간법이 적용된 lr 이미지

600 에폭 후 결과물

High Resolution 이미지
확실히 해상도가 좋아진 것 같긴 하지만, 완벽하게 복원되지는 않는 것 같다.
Review
이번에는 SR in Deep Learning의 간단한 모델인 SRCNN에 대해서 공부해봤습니다.
CNN의 기초적인 특징과 전통적인 SR의 과정이 매우 닮아 있다는 것을 알게된 것이 가장 큰 가치라고 느꼈고, 요즘엔 복잡한 모델들이 많은데 SRCNN은 3개의 레이어만으로도 꽤 괜찮은 성능을 낸다는 것이 신기했습니다. ㅎㅎ



