구현 코드 : https://github.com/yhy258/NCSN_pytorch
GitHub - yhy258/NCSN_pytorch: Notebook
Notebook. Contribute to yhy258/NCSN_pytorch development by creating an account on GitHub.
github.com
ipynb 형식..
얼마전부터 paperswithcode 를 들어가서 image generation 성능 순위를 보면 Score matching based model이 꼭 상위권에 있어서 자꾸 눈에 밟히더라구요.. 그래서 언젠가 꼭 한번 읽어야지 읽어야지 하다가 이제야 읽어보게 됐습니다.
DDPM하고 비슷한 method이더라구요. DDPM 논문을 보면 Langevin Dynamics라는 용어가 나오는데, 이 논문을 읽으니까 대략 어떤 의미로 사용되었는지 알게 되었습니다!
Introduction
Generative model은 보통 \(p_{data}(x)\), 즉 데이터의 pdf를 알아가는 과정으로 묘사합니다. 해당 데이터의 분포를 완전히 이해하면 당연히 데이터를 만들어내는것도 가능하니까요
그럼 Score matching이란 뭘 의미할까요?

위의 figure 처럼 데이터의 pdf를 알고있다고 해봅시다. 그러면 어떤 Noise를 넣고 Gradient Ascent처럼 update 하게되면 실제 데이터에 가까운 형식으로 바뀌게 됩니다.
score를 \(\nabla_x \log{p_{data}(x)}\)로 정의합니다. 처음 무작위 값을 넣어놓고 score를 특정 스텝만큼 계속 더해나가면 실제 샘플에 가깝도록 되겠죠 ??

위의 식을 사용해서 샘플링하는 방법을 Langevin method라고 합니다. 보면 위에서 언급했듯이, 이전 step의 data에 score를 계속 더해나가면서 update 시키는 방법입니다.
(Langevin dynamics는 원래 동역학에서 브라운운동을 설명하기 위한 식입니다. 근데 그 식을 Data generation 분야에 맞춰 식을 만든 것 같네요)

단변수 pdf가 아닌 변수가 2개인 다변수 pdf 를 생각해보면 Score가 위의 그림처럼 형성되게 됩니다. 각 위치의 Gradient는 저렇게 표현되는데 이를 Vector Field 라고 합니다. 색이 있는 곳은 실제 데이터 분포를 의미합니다.
Denoising Score Matching
위의 방법처럼 하려면 score를 알아야하는데 data에 대한 pdf는 알 수 없습니다. (intractable)
tractable한 형태로 바꿔주기 위해 어떤 trick을 사용해주게 되는데요,

위의 식처럼 score network \(s_{\theta}(\tilde x)\)를 하나 만들어줍니다. 그리고 원래 데이터 분포의 score를 근사하는 \(\nabla_{\tilde x}\log{q_\sigma}(\tilde x | x)\) 와 동일하게 되도록 학습시켜줄겁니다.
근데 여기에서 \(\nabla_{\tilde x}\log{q_\sigma}(\tilde x | x)\) 는 뭘까요?
위에서 언급했듯이 \(\log p_{data}(x)\)는 알 수 없기 때문에 이에 대한 score도 알 수 없습니다. 그래서 이런 intractable한 형식 대신 이와 매우 비슷한 \(log{q_\sigma}(\tilde x | x)\)를 사용합니다.
그리고 \(q_\sigma(\tilde x | x) = N(\tilde x ; x, \sigma^2)\) 입니다.
즉 \(\tilde x = x + \sigma * noise\)가 되겠네요.
주어진 data에다가 표준편차가 \(\sigma\)인 가우시안 노이즈를 더한 형태입니다. 이런식으로 노이즈를 더하게 되면 tractable한 pdf 가 됩니다!
이렇게 되면 Gaussian distribution 형식이 되고, log를 붙이면 exponential 부분에 대해 미분하기가 더 쉬워집니다.

미분하면 위처럼 나옵니다!
그래서 위에서 제시한 Eq2 식에 대해 score network를 훈련시키면 되는거구요! 별로 어렵지 않습니다 :)
Challenges of score-based generative modeling
The Manifold Hypothesis
Manifold hypothesis : 실제 세계의 data는 low space의 manifold에 상주한다.
위의 가정이 성립한다면 score matching에 안좋은 영향을 미치게됩니다. score 자체는 expectation을 통해서 관찰된 data에 대해 근사되는 형식으로 진행되면서, dimension 또한 상당히 큽니다. 만약 실제 data가 low space manifold에 상주하게 된다면 당연히 update에 안좋은 영향을 미치겠죠 ??

위 Figure의 좌측은 아무런 처리를 안해준 상태에서의 훈련 진행 결과입니다. 굉장히 안정적이지 않음을 알 수 있습니다.
그래서 저희는 관찰된 데이터를 high space 로 끌어 올려줄 필요가 있습니다.
high space로 끌어올려주기 위해 아주 작은 Gaussian Noise N (0, 0.0001) 를 더해줍니다. perturbed data 라고도 하더군요.
이렇게 가우시안 노이즈를 더해주게 되면 high space에 상주하게 됩니다. 이후 훈련을 한 결과는 Figure 1의 우측에 해당합니다. 굉장히 안정되어있음을 알 수 있습니다.
Low data Density Regions

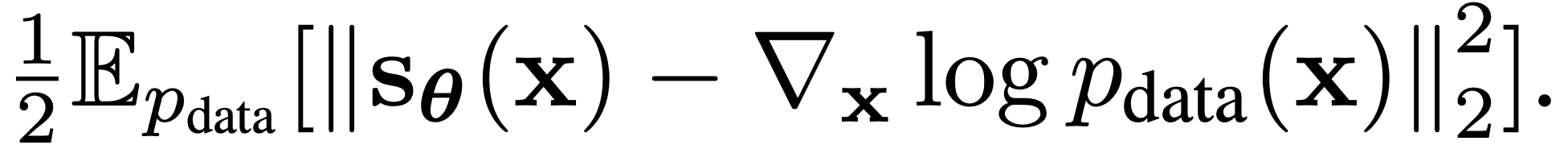
score estimation은 위의 식을 통해 이루어지게 됩니다. data distribution이 expectation으로 계산이 되는데, 관측된 데이터에 대해서만 진행되기 때문에 잘나오지 않는 데이터의 경우 훈련에 참여하기가 어렵습니다. (low density)
Slow mixing of Langevin dynamics

low density 구간으로 인해 2개의 mode 로 구분된 mixture data distribution을 한번 생각해봅시다.
\(p_{data}(x) = \pi p_1(x) + (1-\pi) p_2(x)\) 이런 mixture distribution을 생각해봤을때, 각 support에 대해 score를 구하게 된다면 \(\pi\)값에 독립적이게 됩니다. 그래서 위의 Figure3에서 샘플링 시 비슷하게 나옴을 알 수 있습니다.
Langevin sampling 시 이러한 현상을 막기 위해서는 아주 작은 step, 혹은 아주 큰 step으로 mix를 해야한다고합니다.
이 후 본 논문에서 제시하는 모델에 대해서는 다음에 기술 하겠습니다 !
'Generative Model' 카테고리의 다른 글
| BEGAN : Boundary Equilibrium GenerativeAdversarial Networks (1) | 2022.06.21 |
|---|---|
| EBGAN : ENERGY-BASED GENERATIVE ADVERSARIAL NETWORKS (0) | 2022.06.18 |
| Improved Denoising Diffusion Probabilistic Models : Improved DDPM (0) | 2022.05.18 |
| StyleGAN3 : Alias-Free Generative Adversarial Networks (2) (0) | 2022.05.01 |
| StyleGAN3 : Alias-Free Generative Adversarial Networks (1) (0) | 2022.04.24 |


