Abstract
Flow based model은 tractability라는 특성을 가지고 있어서 굉장히 매력적이고 연구할 가치가 있습니다.
여기에서 tractability는 exact log-likelihood, exact latent variable inference에 대한 tractability를 의미합니다.
그리고 Flow based model이 메리트를 갖으면서 작동하기 위해서는 이전 NICE 논문 포스팅과 Real NVP 논문 포스팅에서 계속 언급해왔듯이 Invertible 해야하고 변수가 바뀌면서 나타나는 volume의 변화를 쉽게 구할 수 있어야 합니다.
이로 인해 Flow based model이 갖을 수 있는 메리트는 근사가 아닌 invertible transformation을 통해 exact하게 작동한다는 것이고 굉장히 efficient 하다는 것 입니다.
Proposed Generative Flow


이 Glow 논문에서 제안하는 방법을 대략적으로 기술하겠습니다.
우선 크게 Actnorm, invertible 1 x 1 convolution, coupling layer로 이루어져 있습니다.
Actnorm : scale and bias layer with data dependent initialization
이전 Real NVP 논문에서는 Batch normalization 기법을 사용해서 deep models를 훈련시킬 때 나타나는 문제들을 줄이고자 했습니다.
하지만 이런 batch normalization의 사용은 PU 당 할당되는 미니배치의 수를 줄이게 됩니다. (메모리 관련 문제)
실제로 큰 이미지가 들어올 때는 1개의 이미지밖에 할당하지 못합니다.
이를 해결하기 위해 actnorm 이라는 레이어를 구상하는데요.
actnorm은 Affine transformation 형태의 레이어로 처음에 scale, bias parameter를 초기화하게 됩니다. 이 초기화 방법은 들어오는 input에 affine transformation이 적용할 때 해당 미니배치에 대하여 zero mean, one variance가 되도록 하는 것 입니다.
그리고 그 후에는 그냥 파라미터 훈련시키듯이 놔둡니다.
그리고 어느 layer처럼 scale에 대해서 log determinant를 구하게 됩니다.
Invertible 1x1 Convolution
각 flow의 step은 variables에 대한 일련의 permutation이 보장되어야합니다.
이 논문에서는 이 channel에 대한 permutation을 고려하게 하는 것이 1x1 convolution과 동일하다 라고 하고 있습니다. 이 때 weight matrix는 무작위의 rotation matrix로 초기화 시키는데 이는 qr module을 통해 구현 할 수 있습니다. (직교행렬은 rotation matrix 이기 때문.)
이 논문에서는 input channel과 output channel이 같은 1x1 convolution은 permutation operation의 generalization 이라고 말하고 있습니다.
이 Invertible 1x1 Convolution layer에서 또한 Jacobian log determinant를 구해야하는데,
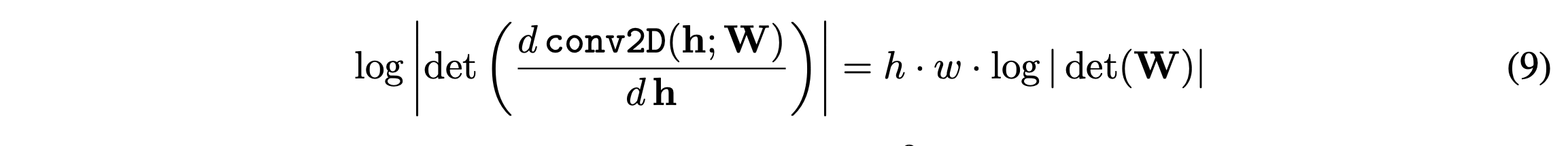
jacobian determinant의 수식에 따르면 우항처럼 단순화 됩니다.
근데 여기에서 W의 determinant를 구하는 것은 computational cost가 많이 듭니다. 그래서 논문에선 LU Decomposition을 제안합니다.
LU Decomposition
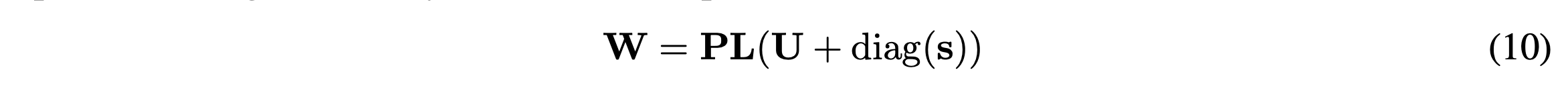

주어진 어떤 정방행렬에 대해서 LU 혹은 PLU 분해를 적용할 수 있습니다. 이 때 Upper Triangular matrix U에 대해 eq (10)처럼 diagonal component를 분리할 수 있습니다.
그래서 이렇게 PLU 분해를 한 상태로 훈련을 진행하게 된다면 determinant를 구하는데 훨씬 수월해질 수 있습니다.
Affine Coupling Layer
Real NVP 때와 동일하게 Affine Coupling Layer를 차용합니다.
이 때 위 Table 1의 NN()의 마지막 convolution은 0으로 초기화 합니다. 이를 통해서 아주 깊은 네트워크를 구성할 수 있었다고 합니다.
그리고 여러 레이어를 쌓아가면서 multi scale을 고려해주기 위해 Real NVP에선 split과 concatenate를 잘 활용했습니다.
하지만 Glow에서는 concatenate없이 split만 사용하며, 훈련을 간소화 하기 위해 split을 channel dimension에 대해서만 수행합니다.
'Generative Model' 카테고리의 다른 글
| StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets (0) | 2022.04.17 |
|---|---|
| Flow++ : Improving Flow-Based Generative Models with Variational Dequantization and Architecture Design (0) | 2021.10.10 |
| Density Estimation Using Real NVP (0) | 2021.09.26 |
| NICE : Non-linear Independent Components Estimation (0) | 2021.09.24 |
| PixelCNN의 실행 흐름 (0) | 2021.09.22 |



